Also: I (and others) frequently decry the medias habit of only reporting sensationalised science; yet I think I probably spend most of this blog discussing such myself. Admittedly in an attempt to explain rather than sensationalise. But as a (possibly rather boring) antidote, here I shall discuss my most recent paper: Connolley, W. M. Sea ice concentrations in the Weddell Sea: A comparison of SSM/I, ULS, and GCM data. GEOPHYSICAL RESEARCH LETTERS 32 (7): art. no. L07501 APR 2 2005. The figures here are taken from the paper.
So: the issue: we run coupled ocean-atmosphere GCMs, which produce (amongst many other things) a field of sea ice concentration and depth in both hemispheres, and we would like to know whether they are right or not. I only do the SH. A simplifying factor there is that we have so few observations of sea ice depth that there is rather little hope of verifying the model depths, so we can stick to ice concentration, which since 1979 has been observed by satellite (there are earlier obs by sat, since 1973, but pretty well everyone agrees that these can't be merged consistently into the later series). This is done by SSMR/SSMI, which is special sensor microwave radiometer or imager, and you can read more about it at wiki. Basically you observe the upwelling microwave radiation in a couple of frequency bands (microwaves are good because they mostly go through clouds and stuff), and their horizontal and vertical polarisation, and from various ratios you then have a quantity that can be related to sea ice concentration. This then gives you a daily field of sea ice concentration.
But, there is more than one way to do this. There are various issues (weather filters, tie points, etc etc) but the man point is that there are two main algorithms, viz the Bootstrap and the NASA Team (there are lots of others too: change the tie points and you can have your own. But its chosing what to ratio to what that is more interesting). I won't tell you the technical differences for the very good reason that I can't remember them. There is (rather well hidden underneath) some politics in all this: and if you probe people carefully they tend to tell you that intercomparisons favour the Bootstrap, but since people had worked on Team that they weren't about to give it up. Certainly the intercomparison papers I read and ref'd in the paper favour Bootstrap, but, err, they were written by the Bootstrap authors. OTOH if the Team folks wrote similar intercomparisons I failed to find them.
 Anyway: the other thing about Team is that until fairly recently it was the only one I had access too, and that my model (HadCM3) produced sea ice that had higher ice concentrations than Team (it also produced ice in a pattern around Antarctica that was somewhat wrong, but for the purposes of this I'm going to ignore the pattern and talk only about the concentration). Then I got access to Bootstrap and discovered that Bootstrap concentrations were higher than Team (though still a bit less than HadCM3). Imagine my delight: we could abandon those efforts to make the model produce less ice and just change the obs. But... this is a bit unsatisfying. We need some obs to verify the obs. So bring on... ULS (upward looking sonar) which sit under the sea for a year or two, going "ping!" every now and again and (after being retrieved and a whole pile of clever data processing to remove wave heights etc) producing a signal for "is there any ice above me" every 5 mins or so. Which can be averaged, over a month, into an ice concentration at a point. And there were about 8 of them in the Weddell sea - see pic. So, spiffy, we can compare them to the Bootstrap and Team data.
Anyway: the other thing about Team is that until fairly recently it was the only one I had access too, and that my model (HadCM3) produced sea ice that had higher ice concentrations than Team (it also produced ice in a pattern around Antarctica that was somewhat wrong, but for the purposes of this I'm going to ignore the pattern and talk only about the concentration). Then I got access to Bootstrap and discovered that Bootstrap concentrations were higher than Team (though still a bit less than HadCM3). Imagine my delight: we could abandon those efforts to make the model produce less ice and just change the obs. But... this is a bit unsatisfying. We need some obs to verify the obs. So bring on... ULS (upward looking sonar) which sit under the sea for a year or two, going "ping!" every now and again and (after being retrieved and a whole pile of clever data processing to remove wave heights etc) producing a signal for "is there any ice above me" every 5 mins or so. Which can be averaged, over a month, into an ice concentration at a point. And there were about 8 of them in the Weddell sea - see pic. So, spiffy, we can compare them to the Bootstrap and Team data.Incidentally, note that this is a thing that happens: I didn't set out to write a ppaer about different sea ice concentration datasets, it just became obvious that I needed to know about this to validate the model and (inconveniently) no one else had done it already.
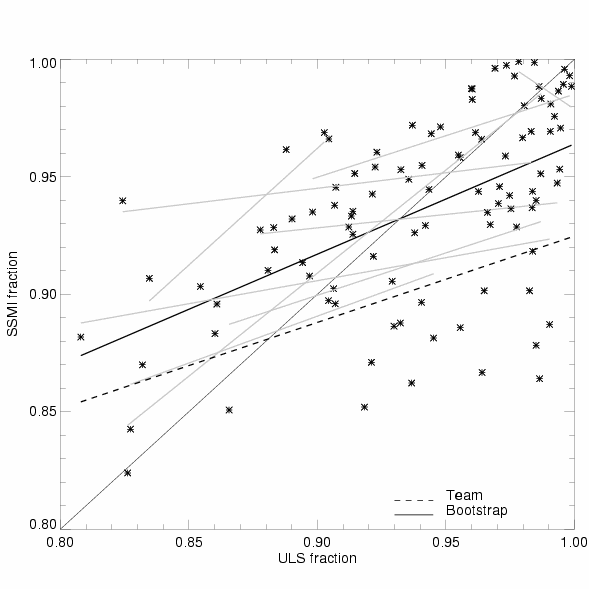 And... we discover that the ULS doesn't fit brilliantly to Team *or* Bootstrap, but it does fit better to Bootstrap. The pic is a scatter plot, with ULS values on the x axis and SSMI (contemporaneous and colocated) on the y. The one-to-one line is where we want all the points to be. The thicker dashed line is a least-squares fit of all these points, using Bootstrap data. The thinner dashed is for Team (and to confuse you, the points are not plotted for Team, just the line). The grey (gray?) lines are what happens when you do the least-squares fitting at just the individual ULS's, instead of aggregating them.
And... we discover that the ULS doesn't fit brilliantly to Team *or* Bootstrap, but it does fit better to Bootstrap. The pic is a scatter plot, with ULS values on the x axis and SSMI (contemporaneous and colocated) on the y. The one-to-one line is where we want all the points to be. The thicker dashed line is a least-squares fit of all these points, using Bootstrap data. The thinner dashed is for Team (and to confuse you, the points are not plotted for Team, just the line). The grey (gray?) lines are what happens when you do the least-squares fitting at just the individual ULS's, instead of aggregating them.On the whole, I (and most people I spoke to) tend to assume that the ULSs are probably right, and therefore interpret the scatter on the plot as a measure of the SSMI retrieval being wrong. OTOH, there is a difficulty in meshing the ULS (point measurements with fine temporal resolution averaged up to monthly scale) to the SSMI (which has a 25 km^2 footprint, which I've averaged up to about 100 km^2, and is daily but I've averaged up to monthly). Quite how much scatter you expect from this, if the ULS and SSMI were both exactly "right", I don't know. But I haven't yet found a good reason why there should be a *bias* between them (ie, why the dashed line on the plot isn't 1-to-1). If you know a good reason, its safe to tell me: the paper is now published, and any new ideas can be fed into a new publication :-).
So the end result of all this? The paper says that sea ice concentrations, at least in the Weddell sea, are probably higher than most people thought they were, and quite possibly even higher than Bootstrap says. And that consequently we can stop worrying much about HadCM3 concentrations. Sadly, it looks like HadGEM concentrations are rather lower... but you can't have everything.
ps: I've decided I'm vaguely keen on explaining my work, so, if anything in the above is not explained, baffling, obviously wrong, whatever, do feel free to comment and I'll try to expand.
No comments:
Post a Comment